

Introduction to Gudu SQLFlow Indirect Data Flow and Pseudo Columns
Gudu SQLFlow Indirect Data Flow & Pseudo Columns Introduction
This article describes some of the SQL elements that generate indirect data flow. Indirect data flow is typically generated by columns used in where clauses, group by clauses, aggregate functions, etc.
To create indirect data flow between columns, we introduce a pseudocolumn: RelationRows.
RelationRows is a pseudocolumn of the relation, used to represent the number of rows in the relation. As the name suggests, RelationRows are not true columns in a relation (table/result set etc).
Typically, it is used to represent the flow of data between columns and relationships. The RelationRows pseudo-column can be used in both source and target relationships.
1. RelationsRows in the target relationship
Take the following SQL as an example:

The total number of rows in the select list is affected by the value of the sal column in the where clause. Therefore, the indirect data flow is created like this:
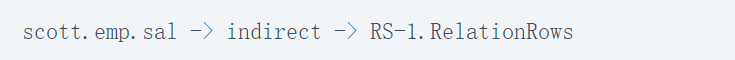
Data flow diagram:

2. RelationsRows in the source relation
Here is another example SQL:

The value of the count() function and sum(sal) function is affected by the number of rows in the scott.emp source table.

Data flow diagram:
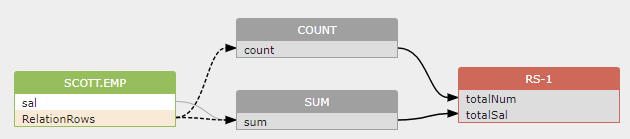
3. RelationshipsRows in table-level data flow relationships
RelationRows are also used to represent table-level data flows.

Table-level data flow is not built on the table, but on the pseudo column RelationRows, like this: t2.RelationRows -> direct -> t3.RelationRows

There are two reasons to use the RelationRows pseudo-column to build a table-to-table data flow:
- This pseudo-column used to represent the table-to-column data flow will later be used to generate the table-to-table data flow if the user needs a table-level provenance model.
- If other columns from the same table are used in a column-to-column data flow that is itself in a table-to-table data flow, then this pseudo-column will enable a single table to contain both column-to-column data flow and table-to-table data flow.
Take this SQL as an example:

The first create view statement will generate a column-level data flow between table t2 and view v1:

And the second alter table statement will generate table-level data flow between tables t2 and t3.

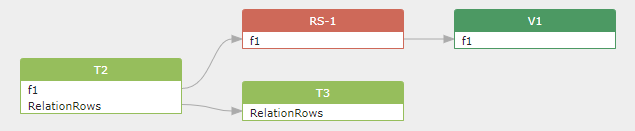
As you can see, table t2 involves the column-to-column data flow generated by the create view statement. It also involves the table-to-table data flow generated by the alter Table statement, as shown in a table t2 in the figure above, which includes both column-to-column and table-to-table data flow.
Conclusion
Thank you for reading our list and we hope it can help you to have a better understanding of the Gudu SQLFlow indirect data flow and pseudo columns. If you want to learn more about Gudu SQLFlow, we would like to advise you to visit their official website for more information.
As one of the best data lineage tools on the market today, Gudu SQLFlow can not only analyze SQL script files, obtain data lineage, and perform visual display, but also allow users to provide data lineage in CSV format and perform visual display.