

Introduction to where-group-by clause in Gudu SQLFlow indirect data flow
In this article, we will introduce where-group-by clauses in Gudu SQLFlow indirect data flow.
1. column in the where clause
Some columns in the source table in the WHERE clause do not affect the target columns, but are critical to the selected rowset, so they should be preserved for impact analysis and indirectly provide the data flow to the target table.
Take the following SQL as an example:
SELECT a.empName “eName” FROM scott.emp a Where sal > 1000
The total number of rows in the select list is affected by the value of the sal column in the where clause, and we establish an indirect data flow for this relationship:
scott.emp.sal -> indirect -> RS-1.RelationRows
The data flow is as shown in the figure:

2. COUNT()
The COUNT() function is an aggregate function that counts the total number of rows for a relationship.
2.1 where clause does not contain group by
Example SQL: SELECT COUNT() num_emp FROM scott.emp where city=1
In the above SQL, two indirect data flows will be created because the value of COUNT() is affected by the city column in the where clause and the total row count of the scott.emp table.

The data flow is shown in the figure:

2.2 where clause contains group by
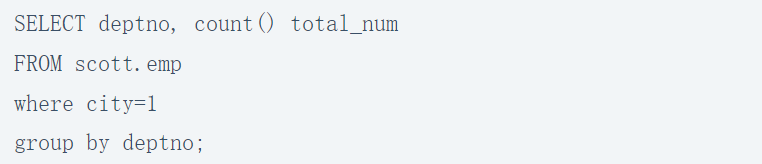
As you can see, in addition to the two indirect data flows created in the preceding SQL, a third indirect data flow was created using deptno in the GROUPBY clause.


3. Other aggregate functions
Other aggregate functions like SUM() work slightly differently than the COUNT() function when creating indirect data flows.
3.1 where clause contains group by

Aggregate functions such as SUM() compute values based on the recordset determined by the columns used in the group by clause, so the deptno column in the group by clause is used to create an indirect data flow to the SUM() function.
An indirect data flow is created from deptno to SUM().

If a group by clause is present, the RelationRows pseudo-column will not be used to create indirect data flows.

3.2 where clause does not contain group by

The above SQL means that the entire recordset of the table will be used to calculate the value of the SUM() function.
Therefore, two indirect data flows will be created as follows:


Conclusion
Thank you for reading our article and we hope it can help you to have a better understanding of where-group-by clause in Gudu SQLFlow indirect data flow. If you want to learn more about Gudu SQLFlow, we would like to advise you to visit their offical website for more information.
As one of the best data lineage tools available on the market today, Gudu SQLFlow can not only analyze SQL script files, obtain data lineage, and perform visual display, but also allow users to provide data lineage in CSV format and perform visual display. Thanks again!