

Get data lineage from an internal database with SQLFlow
Gudu SQLFlow is an automated data lineage tool that specializes in analyzing SQL queries to discover and visualize data lineage that shows the complete data cycle. You can refer to this blog for the introduction.
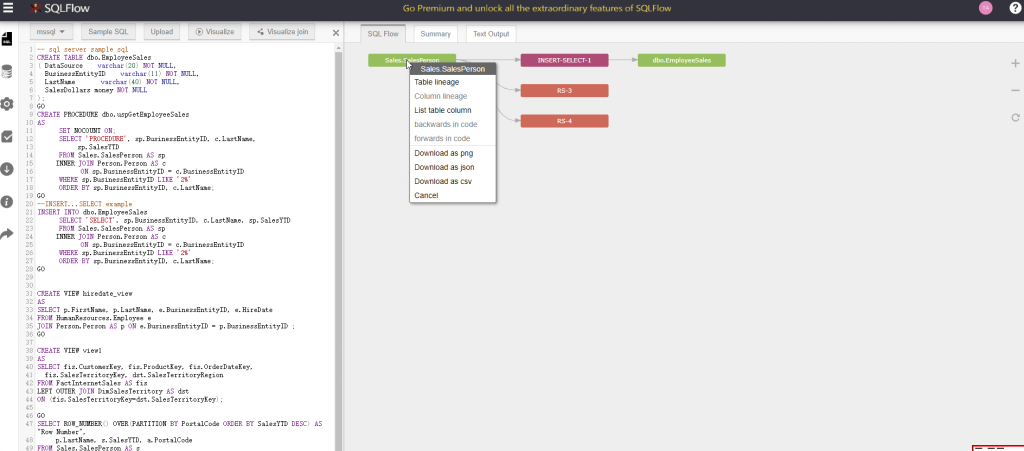
The SQLFlow UI site process thousands of SQL every day and generates data lineages. It is able to read the data source from the online SQL editor, from the SQL scripts uploaded or from client’s database.
One of the most frequent asked is how to use SQLFlow to retrieve data from an internal database where no external network is available. This is a typical usage scenario for our industry customers.
One of the most obvious solutions for the above question is apparently to use Gudu SQLFlow On-Premise on your own server. To archive that, you will need to install and deploy the SQLFlow.
However, what if you prefer not to install any third party software on your internal server?
SQLFlow-Ingester is a tool that helps you to extract metadata from various database. Thanks to SQLFlow-Ingester, we can easily export the database metadata file. The metadata file can be used by Dlineage tool or you can upload the metadata file to SQLFlow UI site to generate data lineage.
Retrieve metadata file
SQLFlow-Ingester script
Let’s say your server is on Linux:
sudo bash exporter.sh
-host 127.0.0.1
-port 1521
-db orcl
-user your_username
-pwd your_password
-save /tmp/sqlflow-ingester
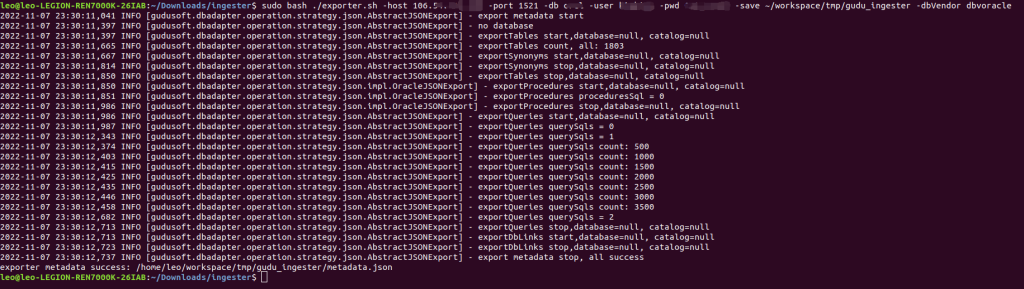
-dbVendor dbvoracleAfter the execution of the script, you will have your internal database metadata file in the /tmp/sqlflow-ingester folder.
If the database server is on Windows, the command is similar:
exporter.bat
-host 127.0.0.1
-port 1521
-db orcl
-user scott
-pwd tiger
-save c:\tmp\sqlflow-ingester
-dbVendor dbvoracleEmbed the SQLFlow-Ingester in your Java code
If you intend to analyze the database and get the data lineage on code level, you can embed the SQLFlow-Ingester in your Java programme:
//1.import the following Ingester library
import com.gudu.sqlflow.ingester.exporter.SqlflowExporter;
import com.gudu.sqlflow.ingester.library.domain.DataSource;
import com.gudu.sqlflow.ingester.library.domain.DbVendor;
import com.gudu.sqlflow.ingester.library.domain.sqlflow.SQLFlow;
import com.gudu.sqlflow.ingester.library.result.Result;
//2.Give the database parameters before invoking the Ingester
DataSource source = new DataSource();
//database host name (ip address or domain name)
source.setHostname("localhost");
//port
source.setPort("3306");
//database name
source.setDatabase("test");
//user namer
source.setAccount("root");
//database password
source.setPassword("123456");
//Database type and version number, Check "List of Supported dbVerdors" section for a full list of the supported databases.
//The second parameter can be null if no specific version need to be provided
DbVendor dbVendor = new DbVendor("dbvmysql", "5.7");
source.setDbVendor(dbVendor);
//Export the metadata, the result can be in object/json string.
SqlflowExporter exec = new SqlflowExporter();
//Take the result in SQLFLow object
Result<SQLFlow> result1 = exec.exporterMetadata(source);
//Take the result in json string
Result<String> result2 = exec.exporterMetadataString(source);Jar package
The SQLFlow-Ingester is in Java so you can directly execute the .jar package if you have Java installed on your server, the jar packages are under the ./lib folder:
java -jar sqlflow-exporter-1.0.jar -host 106.54.xx.xx-port 1521 -db orcl -user username -pwd password -save d:/ -dbVendor dbvoracleFollowing are the description for the parameters we support with the tool.
-dbVendor: Database type, Check here for a full list of the supported databases. Use colon to split dbVendor and version if specific version is required. (<dbVendor>:<version>, such as dbvmysql:5.7)
-host: Database host name (ip address or domain name)
-port: Port number
-db: Database name
-user: User name
-pwd: User password
-save: Destination folder path where we put the exported metadata json file. The exported file will be in name as metadata.json.
-extractedDbsSchemas: Export metadata under the specific schema. Use comma to split if multiple schema required (such as <schema1>,<schema2>). We can use this flag to improve the export performance.
-excludedDbsSchemas: Exclude metadata under the specific schema during the export. Use comma to split if multiple schema required (such as <schema1>,<schema2>). We can use this flag to improve the export performance.
-extractedViews: Export metadata under the specific view. Use comma to split if multiple views required (such as <view1>,<view2>). We can use this flag to improve the export performance.
-merge: Merge the metadata results which are exported in different process. Use comma to split files to merge. Check here for more details.You will receive the message if the export is succeeded:
exporter metadata success: /home/leo/workspace/tmp/gudu_ingester/metadata.json
Get data lineage from the metadata file
SQLFlow UI
With the exported metadata.json, we are now ready to retrieve data lineage.
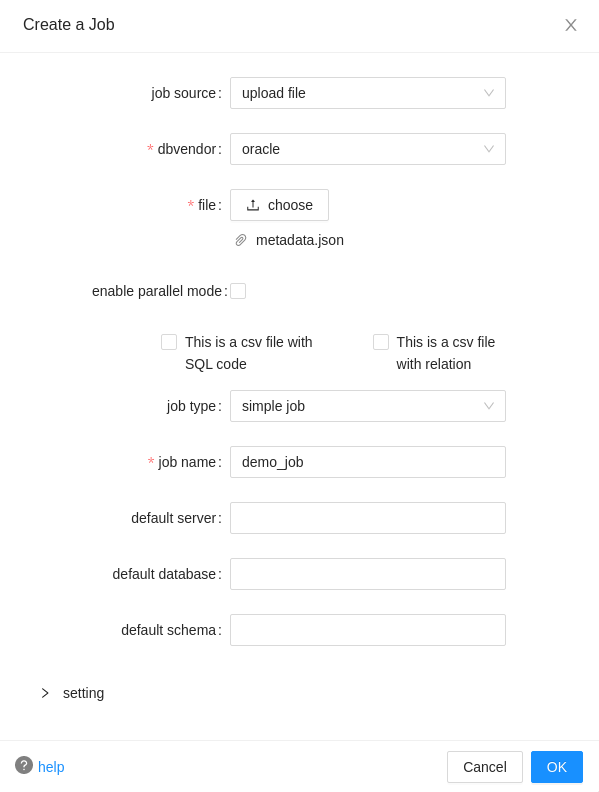
Open your browser and go to our SQLFlow UI. Create a Job with the Job Source as upload file:
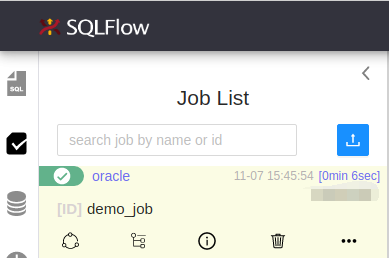
Check the lineage overview/detail once the job is finished.
Dlineage Tool
An alternative way to get the data lineage from the metadata file is to use Dlienage tool:
java -jar gudusoft.dlineage.jar /t oracle /f metadata.jsonConclusion
We can use sqlflow-ingester to export the metadata file from an internal database. The metadata file can be later used in SQLFlow UI or Dlineage tool to retrieve the data lineage.
SQLFlow-Ingester download address: https://github.com/sqlparser/sqlflow_public/releases
Check https://www.gudusoft.com/ for more information and find more extraordinary features of Gudu SQLFlow