

Visualize your data with SQLFlow REST API
Gudu SQLFlow is an analysis software for analyzing SQL statements and discovering data lineage relationships. It is often used with metadata management tools and is a basic tool for enterprise data governance. Check this introduction blog if you don’t know much about Gudu SQLFlow.
Gudu SQLFlow has various functionalities for data lineage generation and it provides you different choices to visualize your data. SQLFlow REST API is one of the most commonly used features. Your data analysis result will be generated and returned from SQLFlow server by sending standard parameterized RESTFul Api request. Apart from report under Json, XML, CSV format, SQLFlow REST API is also able to return result as image(PNG/JPEG) from your SQL.
The API Endpoint
The related SQLFlow Api to visualize your data lineage is:
/sqlflow/generation/sqlflow/graph/imageThe /graph/image accepts either SQL statements text or it can reads from SQL file. Export your database metadata into SQL files if you would like to generate data lineage image for your database with /graph/image. (tips: you can use SQLFlow Ingester to export metadata files from your database)
Let’s use the following SQL statements to see how to sort out the data dependencies between various tables/views with a simple call to SQLFlow REST API:
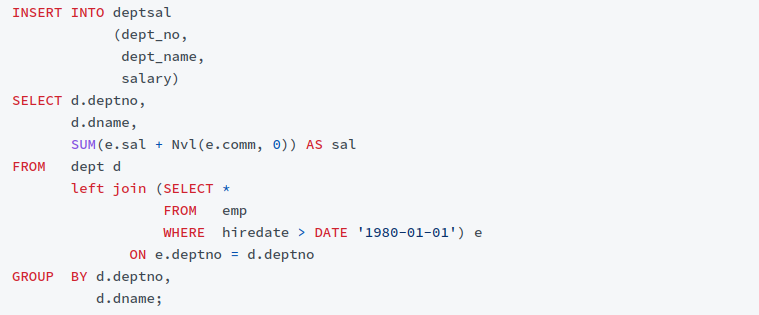
By analyzing the above INSERT SQL statement, we can know:
The data of the deptsal table comes from the dept and emp tables. Further, the data dependency (data lineage) at the field level is:
- The data of the deptsal.dept_no field comes from dept.deptno;
- The data of the deptsal.dept_name field comes from dept.name;
- The data of the deptsal.salary field comes from emp.sal and emp.comm;
Simply upload the above piece of code to SQLFlow API (or you can put the SQL statements in SQL file in case of the sql statement is complex):
curl --location --request POST 'https://api.gudusoft.com/gspLive_backend/sqlflow/generation/sqlflow/graph/image' \
--header 'accept: image/*' \
--form 'sqlfile=@"/home/test.sql"' \
--form 'dbvendor="dbvoracle"' \
--form 'userId="<YOUR USER ID>"' \
--form 'token="<THE GENERATED TOKEN>"'Result:
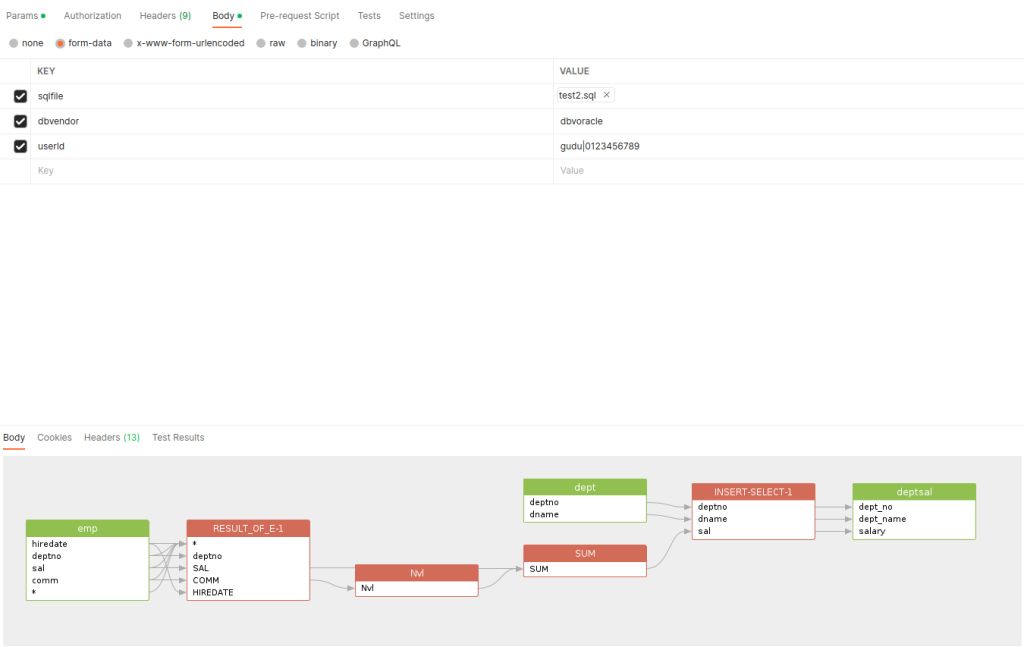
Hint: SQLFlow On-Premise is used in the above capture, hence token is not required and only userId is given in param. Please refer to this document to check how to get the userid and the token.
Request Parameters
In the above request, only sqlfile, dbvendor and userId are given as the request parameters. The sqlfile is the file that you are going to upload. Use sqltext If you prefer use SQL text. The dbvendor tells SQLFlow to what database this SQL is based on. Other request parameters are not required and have default value. However, you can apply all SQLFlow settings to customize the output image. Check the following table:
| Field name | Type | Description |
| dbvendor | string | database vendor, support values: – dbvazuresql – dbvbigquery – dbvcouchbase – dbvdb2 – dbvgreenplum – dbvhana – dbvhive – dbvimpala – dbvinformix – dbvmdx – dbvmysql – dbvnetezza – dbvopenedge – dbvoracle – dbvpostgresql – dbvredshift – dbvsnowflake – dbvmssql – dbvsparksql – dbvsybase – dbvteradata – dbvvertica |
| hideColumn | boolean | whether hide column |
| ignoreFunction | boolean | whether ignore function |
| simpleOutput | boolean | simple output, ignore the intermediate results, defualt is false. |
| ignoreRecordSet | boolean | same as simpleOutput, but will keep output of the top level select list, default is false. |
| jobId | string | give the job Id if need to use the job settings and display the job graph |
| normalizeIdentifier | boolean | whether normalize the Identifier, default is true |
| showTransform | boolean | whether show transform |
| sqltext | string | sql text from which to generate the sqlflow model |
| token | string | The token is only used when connecting to the SQLFlow Cloud server, It’s not in use when connect to the SQLFlow on-premise version. |
| treatArgumentsInCountFunctionAsDirectDataflow | boolean | Whether treat the arguments in COUNT function as direct Dataflow |
| userId | string | the user id of sqlflow web or client |
| columnLevel | string | whether to show table level or column level data, false or true |
Image Data Lineage Result

Let’s use the following settings and make the output more easier to understand:
| Field name | Value |
| showRelationType | fdd |
| treatArgumentsInCountFunctionAsDirectDataflow | true |
| ignoreRecordSet | false |
| ignoreFunction | true |
| showConstantTable | false |
| showTransform | false |
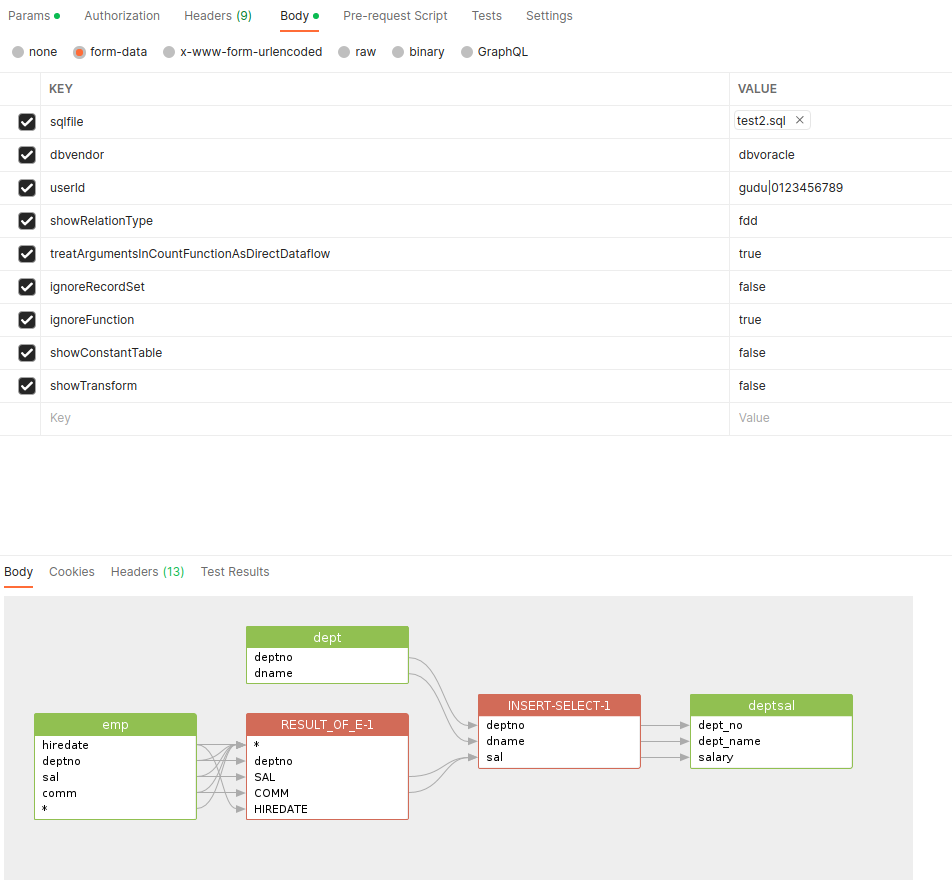
All database objects discovered during the data lineage analysis are stored in the $.dbobjs object.
Table
There are four tables founded in the above result:
- DEPTSAL: you can use
$.dbobjs[1].nameto return the table name, and$.dbobjs[1].typeto return the type of this object which istablein this case. you can also use expression like this to get this table:
$.dbobjs[?(@.name=='deptsal')].name- DEPT
$.dbobjs[?(@.name=='dept')].name- EMP
$.dbobjs[?(@.name=='emp')].name- SQL_CONSTANTS: This is not a real table, but a table generated by the Gudu SQLFlow to store the constant used in the SQL query.
$.dbobjs[?(@.name=='SQL_CONSTANTS')].nameOnline Web Tool
You can get more information about SQLFlow with the online demo. The online web tool uses SQLFlow API to generate the result. You can also build your own web tool with the help of SQLFlow REST API. Check this fantastic data visualization tool today!