Visualize your upstream/downstream data with SQLFlow REST API
Gudu SQLFlow is an analysis software for analyzing SQL statements and discovering data lineage relationships. It is often used with metadata management tools and is a basic tool for enterprise data governance. Check this introduction blog if you don’t know much about Gudu SQLFlow.
When dealing with complex SQL statements, we can check the data upstream or data downstream analysis by using the to upstream/to downstream feature of SQLFlow.
To upstream/downstream
SQLFlow UI provides the upstream/downstream data analysis in regular SQLFlow Job by right clicking the data element.
The upstream of the data gives the source lineage for the selected data. Given full data lineage a -> b -> c, if data element b is selected for its upstream, the upstream lineage would be a -> b.
On the contrary, the downstream of the data returns the affected lineage for the selected data. Given full data lineage a -> b -> c, if data element b is selected for its upstream, the upstream lineage would be b -> c.
Let’s take the following data lineage as an example:

The upstream of the hr.dbo.countries would be:

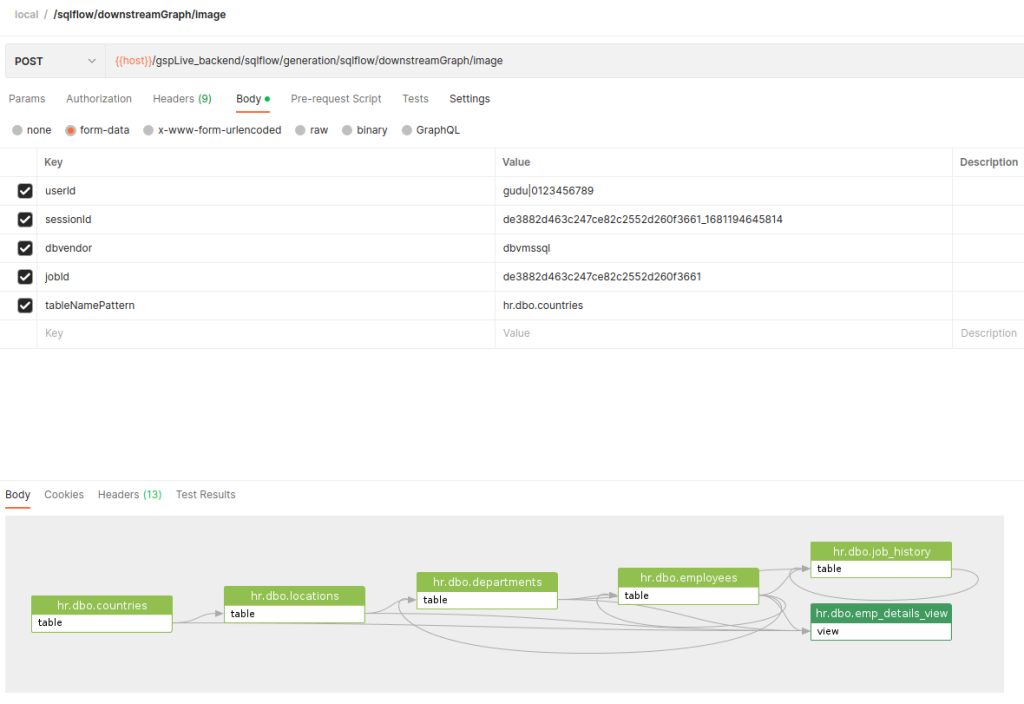
The downstream of the hr.dbo.countries is:

SQLFlow REST API
Gudu SQLFlow has various functionalities for data lineage generation and it provides you different choices to visualize your data. SQLFlow REST API is one of the most commonly used features. Your data analysis result will be generated and returned from SQLFlow server by sending standard parameterized RESTFul Api request. Apart from report under Json, XML, CSV format, SQLFlow REST API is also able to return result as image(PNG/JPEG) from your SQL.
To visualize the data lineage upstream/downstream with SQLFlow REST API, we need to invoke
/sqlflow/generation/sqlflow/upstreamGraph/image/sqlflow/generation/sqlflow/downstreamGraph/imageThese two endpoints take sessionId as input. There are two ways to get sessionId:
1. Invoke data lineage API to get sessionId
Sample:
curl --location 'https://<SQLFlow url>/gspLive_backend/sqlflow/generation/sqlflow/graph' \
--header 'accept: application/json;charset=utf-8' \
--form 'sqlfile=@"/home/workspace/test2.sql"' \
--form 'dbvendor="dbvoracle"' \
--form 'userId="gudu|0123456789"'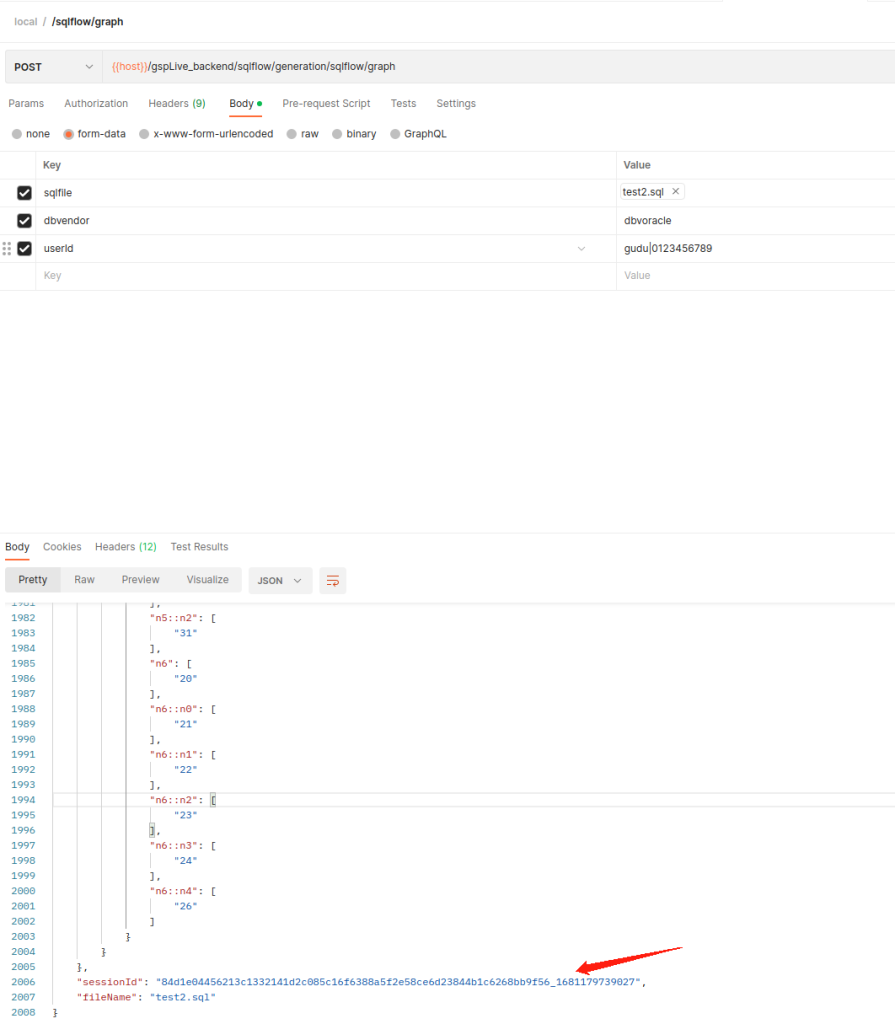
2. Create SQLFlow Job
The following endpoint is to create a SQLFlow:
/sqlflow/job/submitUserJob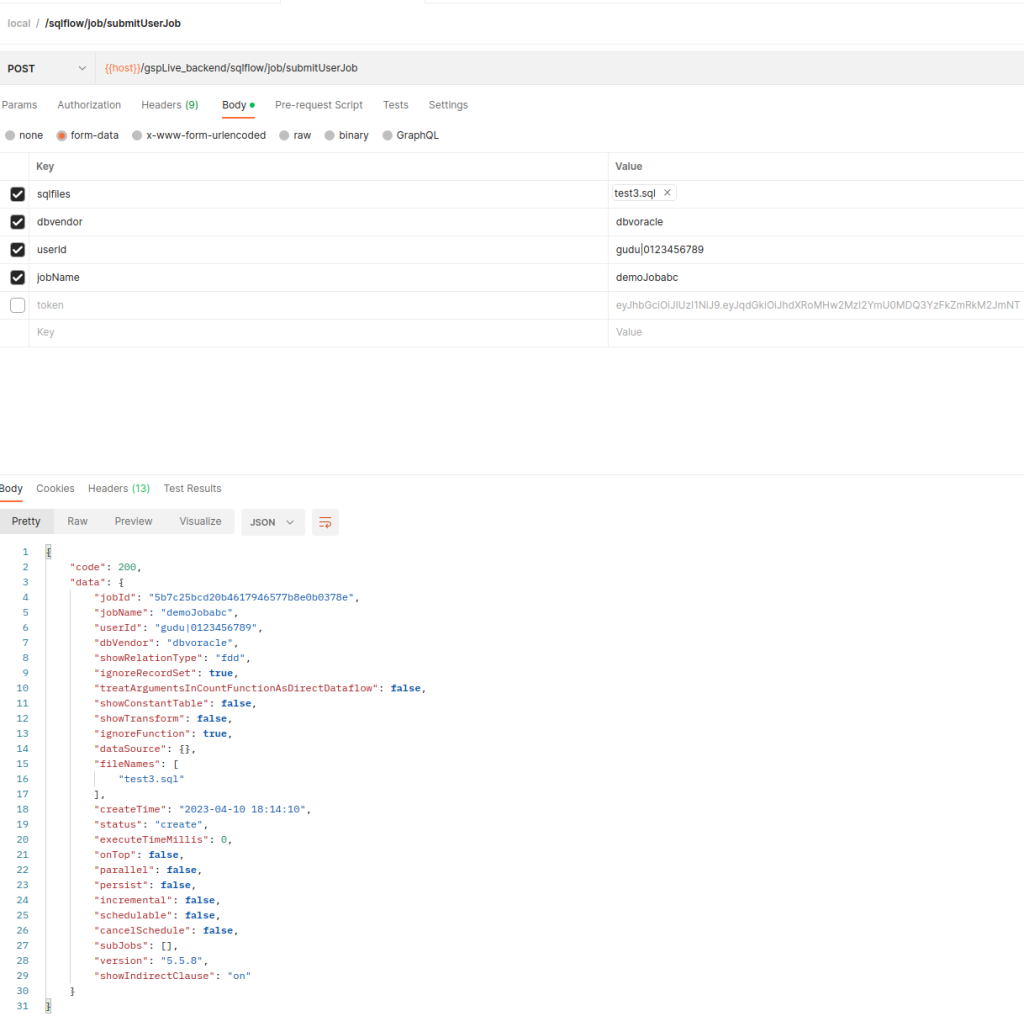
Wait few seconds and If we check our job list, we should have this demoJob2 in our job success list. You can verify that ethiter go to the SQLFlow interface or use another SQLFlow REST API /sqlflow/job/displayUserJobsSummary.
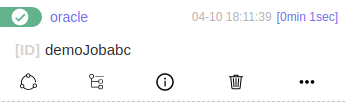
Great! After checking the SQLFlow web, we have confirmed the SQLFlow Job is succeeded.
Now we have our Job created and we need to select our data now. To do that, invoke:
/sqlflow/job/displayUserJobGraphGive the Job Id as the input and in the response of the above API, we will have the sessionId:
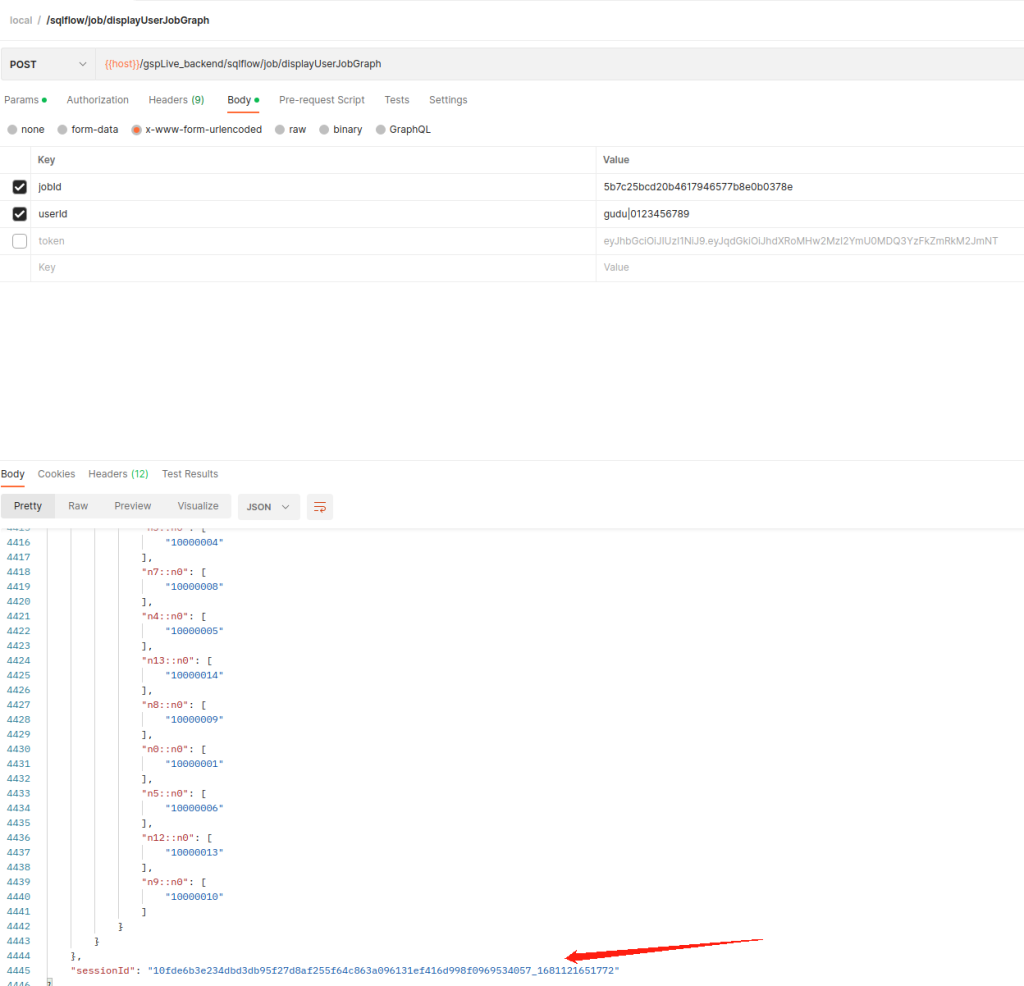
Get upstream/downstream lineage
Now we are good to invoke the upstream/downstream SQLFlow Api with the sessionId ready. You can use tableNamePattern to map the desired table. By default the top SQLFlow Job is taken If sessionId is not given. Full parameter table:
| Field name | Type | Description |
| dbvendor | string | database vendor, support values: – dbvazuresql – dbvbigquery – dbvcouchbase – dbvdb2 – dbvgreenplum – dbvhana – dbvhive – dbvimpala – dbvinformix – dbvmdx – dbvmysql – dbvnetezza – dbvopenedge – dbvoracle – dbvpostgresql – dbvredshift – dbvsnowflake – dbvmssql – dbvsparksql – dbvsybase – dbvteradata – dbvvertica |
| hideColumn | boolean | whether hide column |
| ignoreFunction | boolean | whether ignore function |
| simpleOutput | boolean | simple output, ignore the intermediate results, defualt is false. |
| ignoreRecordSet | boolean | same as simpleOutput, but will keep output of the top level select list, default is false. |
| jobId | string | give the job Id if need to use the job settings and display the job graph |
| normalizeIdentifier | boolean | whether normalize the Identifier, default is true |
| showTransform | boolean | whether show transform |
| token | string | The token is only used when connecting to the SQLFlow Cloud server, It’s not in use when connect to the SQLFlow on-premise version. |
| treatArgumentsInCountFunctionAsDirectDataflow | boolean | Whether treat the arguments in COUNT function as direct Dataflow |
| userId | string | the user id of sqlflow web or client |
| isReturnModel | boolean | whether to return model |
| sessionId | string | the graph session Id |
| showConstantTable | boolean | whether show constant table |
| showLinkOnly | boolean | whether show link only |
| showRelationType | string | show relation type, required false, default value is ‘fdd’, multiple values seperated by comma like fdd,frd,fdr,join. Availables are ‘fdd’ value of target column from source column, ‘frd’ the recordset count of target column which is affected by value of source column, ‘fdr’ value of target column which is affected by the recordset count of source column, ‘join’ combines rows from two or more tables, based on a related column between them |
| tableColumn | string | target table column |
| tableNamePattern | string | target table name, supports regex expression |
| distance | integer | graph element distance |
| stopat | string | stop at |
Upstream Sample:
curl --location 'https://<SQLFlow URL>/gspLive_backend/sqlflow/generation/sqlflow/upstreamGraph/image' \
--header 'accept: image/*' \
--form 'userId="gudu|0123456789"' \
--form 'sessionId="de3882d463c247ce82c2552d260f3661_1681194645814"' \
--form 'dbvendor="dbvmssql"' \
--form 'jobId="de3882d463c247ce82c2552d260f3661"' \
--form 'tableNamePattern="hr.dbo.countries"'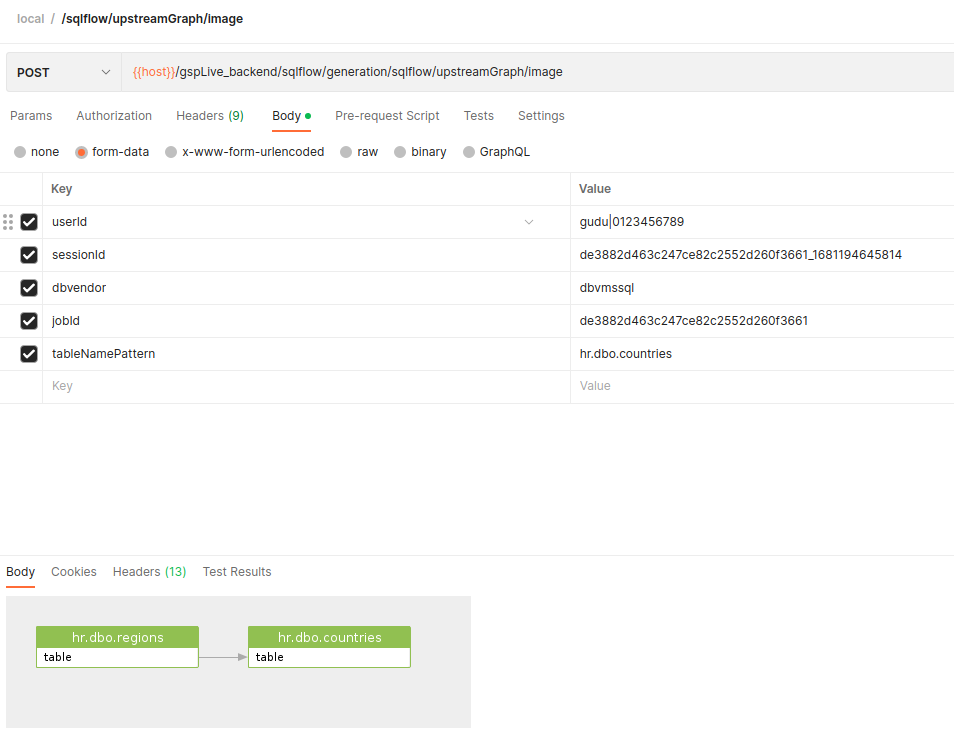
Downstream Sample:
curl --location 'https://<SQLFlow URL>/gspLive_backend/sqlflow/generation/sqlflow/downstreamGraph/image' \
--header 'accept: image/*' \
--form 'userId="gudu|0123456789"' \
--form 'sessionId="de3882d463c247ce82c2552d260f3661_1681194645814"' \
--form 'dbvendor="dbvmssql"' \
--form 'jobId="de3882d463c247ce82c2552d260f3661"' \
--form 'tableNamePattern="hr.dbo.countries"'